The evidence your AI must produce to survive in production.
To prove value after deployment, your system must generate evidence continuously.
RIGOR™ defines how that happens.
Not just for compliance — but for reimbursement, renewal, and scale.
"We don't just assess AI systems — we define what they need to prove."
RIGOR™ defines what evidence your system must produce — from requirements through real-world monitoring.
Not just for compliance, but for reimbursement, renewal, and scale. Most AI systems fail at the evidence layer — not the algorithm layer. RIGOR™ is the operational system that closes that gap.
Most AI teams can answer one question. Very few can answer the four that matter.
📊 How accurate is the model?
Almost every team can answer this. It gets you in the room. It does not close the deal, get you reimbursed, or protect you in litigation.
🏥 What happened after it was used?
Did clinicians accept or override the output? Did outcomes change? Most deployed AI has no mechanism to answer this — ever.
💰 Can you prove that to a payer?
CMS and commercial payers require real-world clinical utility evidence. FDA clearance and CMS reimbursement ask different questions with different evidence standards.
⚖️ Can you produce an audit trail in 30 days?
Only 22% of health system leaders are confident they could. The rest discover the gap when a regulator or plaintiff's attorney asks first.
This is the gap RIGOR™ System addresses
Governance as the architecture that generates the evidence your AI must produce to create commercial value — for payers, for regulators, and for the procurement rooms where health AI deals live or die.
FDA Clearance Is Not CMS Reimbursement. RIGOR™ Closes the Gap.
Only 10% of MedTech companies report meaningful AI revenue impact, versus 25% of biopharma in the same regulatory environment. The gap is not capability — it is evidence design. (BCG, 2026)
FDA Asks
Does this device perform as intended without undue risk?
Technical validation, pre-deployment performance metrics
CMS Asks
Does this improve clinical outcomes, reduce costs, or replace existing billable services?
Real-world outcomes from actual deployment
The 2026 Medicare Physician Fee Schedule activates reimbursement codes for AI-enabled services. Organizations with post-deployment real-world evidence will bill from day one. Organizations with only pre-deployment validation data will not. The RIGOR™ System architecture determines which category your organization occupies.
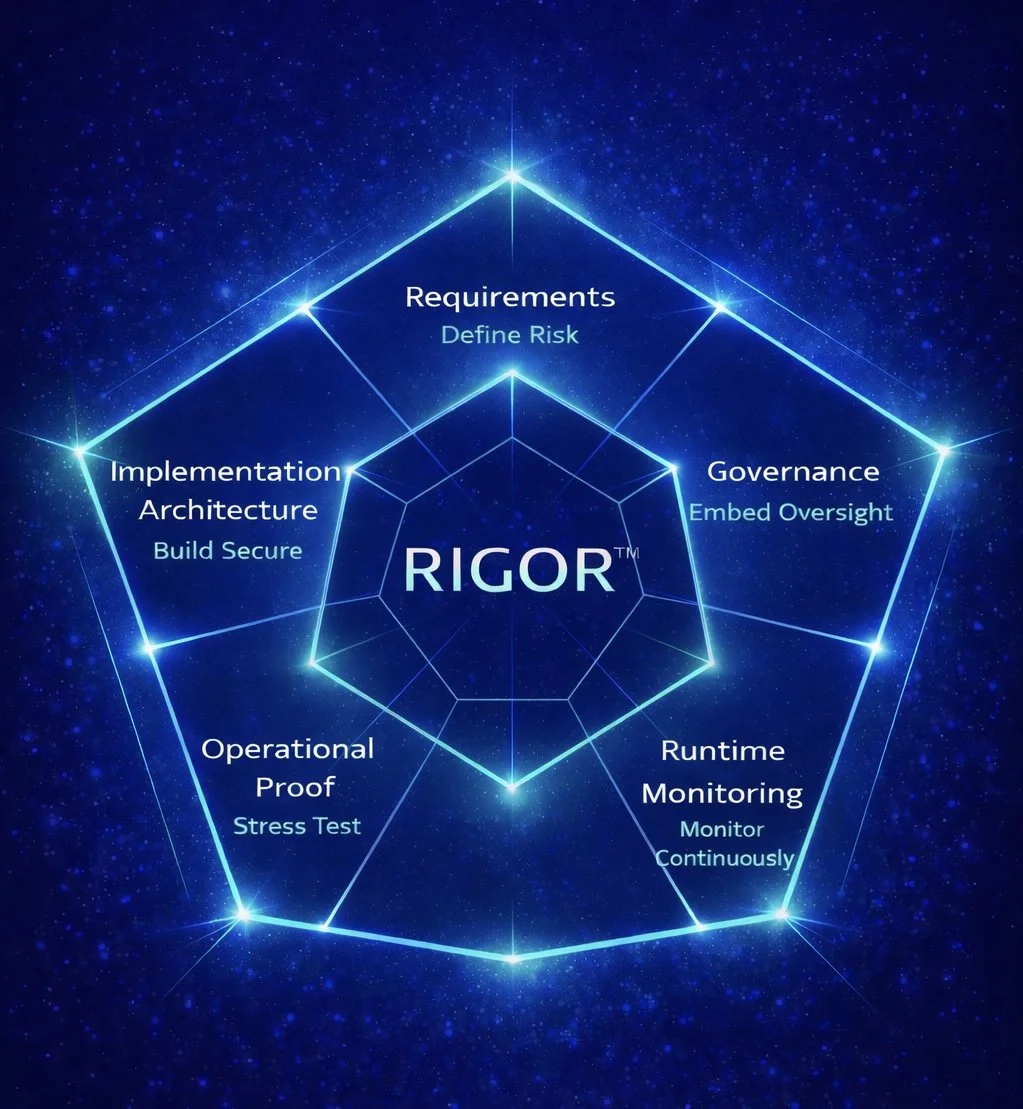
Five Modules. Three Evidence Streams.
Each module builds on the last — generating specific evidence that compounds into simultaneous value for regulators, payers, and legal defensibility.
Requirements Objectives, risk thresholds, metrics, regulatory scope
Implementation Auditable pipelines, bias controls, data lineage
Governance Authority, overrides, audit pathways, RACI
Operational Proof Real-world validation, external datasets, live pilots
Runtime Monitoring Drift, bias, impact evidence, outcome tracking
RIGOR™ System — evidence generation architecture, not just a governance framework
Five Modules. One Evidence Architecture.
Each module must be complete before the next begins. This is not bureaucracy — it is the mechanism that prevents the most common deployment failures and the sequence that generates evidence for regulators and payers simultaneously.
Module 1: Requirements
Define everything before you build anything.
Before a single model is trained, every stakeholder objective, risk boundary, performance metric, and acceptable failure threshold must be formally documented and signed off. This is the gate that prevents building technically correct solutions to the wrong problem — and building solutions whose evidence won't satisfy the audiences that matter commercially.
- Stakeholder objectives documented with clinical and legal sign-off
- Risk thresholds explicitly defined, including false negative limits
- Performance metrics specified with demographic disaggregation requirements
- Acceptable failure thresholds defined with human override triggers
- Regulatory constraints and payer evidence requirements mapped before development begins
Module 2: Implementation Architecture
Build it right the first time. Auditable by design.
Architecture is not an afterthought. Model pipelines, data integrity mechanisms, interoperability standards, security controls, and scalability requirements are designed intentionally and documented completely. The goal is an auditable blueprint — not a patchwork of notebooks.
- End-to-end model pipeline documented with versioning and complete data lineage
- Data quality gates and bias checks built into the ingestion pipeline
- Interoperability standards enforced: HL7 FHIR, API contracts, data schemas
- Security and privacy controls built-in: encryption, access logs, HIPAA/GDPR compliance
- Scalability and failover architecture validated before deployment
Module 3: Governance
Governance is structure, not documentation.
Decision authority, override mechanisms, audit pathways, and accountability mapping are embedded into the system architecture before deployment. If governance lives only in a PDF, it does not exist.
- Decision authority matrix: who approves changes, who can override the AI
- Override mechanisms coded into the system with mandatory audit logging
- Complete audit pathway: every decision traceable to actor, time, data, and context
- RACI mapping complete for all components and failure scenarios
- Accountability structures defensible under regulatory review
Module 4: Operational Proof
The standard is survivability under real conditions, not demo performance.
Laboratory validation is necessary but not sufficient. RIGOR™ requires demonstration of system performance under real-world conditions: dataset shift, environmental noise, edge cases, and human interaction patterns. Critically, this is also where payer-qualifying evidence begins to be generated.
- External validation on independent, demographically representative datasets
- Staged pilot or shadow-mode deployment with live operational data
- Stress testing under dataset shift, environmental noise, and edge cases
- Human interaction validation with target clinical users
- Robustness and safety metrics documented alongside accuracy
Module 5: Runtime Monitoring
Deployment is not the end of accountability — or evidence generation.
Continuous monitoring detects drift, bias emergence, and performance degradation. Formal re-evaluation cycles are scheduled. Most critically: this module tracks whether AI outputs are accepted or overridden by clinicians, how decisions change, and what outcomes follow — generating the impact evidence required for CMS reimbursement renewal, D&O insurance endorsements, hospital contract renewals, and the legal audit trail that clinical environments require.
- Automated drift detection with defined alert thresholds
- Ongoing bias monitoring across protected demographic groups
- Real-world outcome tracking linked back to model predictions
- Clinician acceptance/override rates tracked as commercial evidence
- Scheduled formal re-evaluation cycles — minimum every 12 months
- Incident response protocols with tested rollback capability
"The benchmark-only standard is no longer defensible. Validation is a lifecycle discipline, not a checkbox before launch — and the evidence it generates is a commercial asset, not a compliance cost."– Olga Lavinda, PhD, CEO, Health AI LLC
How RIGOR™ System Maps to Major Regulatory Frameworks
RIGOR™ complements — not replaces — NIST, EU AI Act, and FDA guidance by providing the operational layer that translates governance principles into engineering discipline and commercial evidence simultaneously.
| RIGOR™ Module | NIST AI RMF | EU AI Act | FDA AI/ML Guidance | CHAI |
|---|---|---|---|---|
| Requirements | Govern / Map – context, intended use, stakeholder impacts | Fundamental rights impact assessment, risk identification | Context of use, performance claims, risk controls | Transparency principles, intended use documentation |
| Implementation | Govern + Map – design choices, data quality governance | Technical documentation, robustness, cybersecurity requirements | Design controls, data management, validation planning | Data quality standards, model documentation requirements |
| Governance | Govern function – roles, accountability, oversight mechanisms | Mandatory human oversight, logging, accountability | Pre-market validation + post-market surveillance plans | Human oversight requirements, clinician accountability |
| Operational Proof | Measure function – testing, metrics, evaluation | Conformity assessment under deployment conditions | Independent validation, real-world evidence, pilot requirements | Real-world performance validation, equity testing |
| Runtime Monitoring | Manage function – monitoring, incident response | Post-market surveillance, incident reporting requirements | Continuous monitoring, change protocols, adverse event reporting | Ongoing surveillance, bias monitoring, incident reporting |
Free Download
Want the full system documentation before going deeper?
The white paper covers all five modules, the regulatory crosswalk, and the complete deployment checklist.
Three Failures. Two Implementations.
Three widely documented failures show what happens without structural discipline. Two active implementations show what the RIGOR™ System looks like applied from the start.
AI-Driven Early Warning System – Global Tire & Mobility Leader
The Challenge
A global tire manufacturer faced a decade-long decline in early warning signal quality. Legacy 1990s systems, siloed data, 50% industry-wide parts overallocation, and no early-warning capability for EV tire wear patterns.
Seven major enterprise vendors evaluated — Amazon, Microsoft, IBM, SAS, NTT Data, Dell, and Oracle. None addressed the full problem scope without significant cloud dependency, cost, or data sovereignty loss.
Selected at RFP stage.
RIGOR™ System Application
Stakeholder objectives formally scoped across warranty, NHTSA compliance, EV product lines, and supply chain before any architecture decisions.
Live proof-of-concept at client's Tennessee Distribution Center — actual deployment context. C-suite response: "This could become a national standard."
The Transferable Principle
The core problem in automotive AI and clinical AI is identical: high-stakes decisions made on incomplete, siloed, poorly validated signal where the cost of failure is asymmetric. RIGOR™ is not sector-specific. It is a transferable standard.
Epic Sepsis Prediction Model
What Failed
Deployed across hundreds of U.S. hospitals, external evaluation found substantially lower predictive accuracy than reported. Poor calibration across patient populations with no monitoring framework to detect degradation.
RIGOR™ Analysis
Validation was internal. Independent external evaluation across diverse demographics was absent before deployment.
No post-deployment monitoring tracked real-world outcomes. Performance degradation went undetected across institutions.
IBM Watson for Oncology
What Failed
Never clinically validated in deployment environments. Generated recommendations that conflicted with established guidelines — including recommendations described internally as "unsafe and incorrect."
RIGOR™ Analysis
Gap between actual capabilities and marketed use case was never formally defined before deployment.
No accountability structure for recommendations. No correction pathway when failures emerged.
Racial Bias in Healthcare Risk Prediction
What Failed
A widely deployed algorithm systematically underestimated the healthcare needs of Black patients by using healthcare cost as a proxy for health need — encoding systemic inequity into clinical decisions affecting ~200 million people annually.
RIGOR™ Analysis
Proxy variable selection was never subjected to formal bias review. Risk boundaries for disparate demographic impact were undefined.
Operated for years without bias monitoring. Identified by external researchers, not any internal system.
AI Literacy – Health Professions Education
The Challenge
Embedding AI prompt literacy as a clinical safety competency in undergraduate coursework. Core risk: students using AI tools without understanding failure modes, hallucination patterns, or prompt-quality dependencies — and carrying those habits into clinical roles.
RIGOR™ Application
Stakeholder objectives formalized as clinical safety competency before curriculum design began. Performance metrics specified with cross-model comparison design.
Within-subject cross-model validation (ChatGPT, Claude, Gemini) with structured prompt ladder methodology.
RIGOR™ System Deployment Checklist
A system that cannot check every box in a module before proceeding is not ready for the next stage.
Requirements
- ☐Stakeholder objectives formally documented
- ☐Risk thresholds defined with clinical review
- ☐Metrics with demographic disaggregation
- ☐Human override triggers defined
- ☐Regulatory + payer constraints mapped
Implementation
- ☐Versioned pipeline with data lineage
- ☐Bias checks in ingestion pipeline
- ☐Interoperability standards enforced
- ☐Security and privacy controls verified
- ☐Infrastructure reliability tested
Governance
- ☐Decision authority matrix defined
- ☐Override mechanisms coded in-system
- ☐Complete audit pathway established
- ☐RACI mapping complete
- ☐Legal and compliance reviewed
Operational Proof
- ☐External validation completed
- ☐Shadow-mode pilot conducted
- ☐Stress testing under real conditions
- ☐Human interaction validated
- ☐Payer evidence baseline documented
Runtime Monitoring
- ☐Drift detection implemented
- ☐Bias monitoring configured
- ☐Outcome tracking established
- ☐Acceptance/override rates tracked
- ☐Re-evaluation schedule defined
Questions About RIGOR™ System and AI Evidence Architecture
What is the RIGOR™ System?
The RIGOR™ System is a five-module, full-lifecycle AI validation and governance system developed by Dr. Olga Lavinda at Health AI LLC. RIGOR stands for Requirements, Implementation Architecture, Governance, Operational Proof, and Runtime Monitoring. Each module must be completed sequentially before the next begins. It generates evidence for FDA regulatory requirements, CMS payer reimbursement, and legal defensibility simultaneously — making governance a revenue strategy, not a compliance cost.
What is the gap between FDA clearance and CMS reimbursement for AI medical devices?
FDA and CMS ask fundamentally different questions. FDA asks whether a device performs as intended without undue risk — answered by technical validation and pre-deployment performance metrics. CMS asks whether the device improves clinical outcomes, reduces costs, or replaces existing billable services — answered by health economic studies and real-world outcomes from actual deployment. These evidence standards are orthogonal. A company can achieve FDA 510(k) clearance with zero reimbursement-qualifying evidence. The RIGOR™ System's Operational Proof and Runtime Monitoring modules are specifically designed to generate evidence satisfying both audiences simultaneously.
Why do most AI deployments fail in healthcare?
Most AI failures in healthcare are structural, not algorithmic. They result from gaps in requirements definition, governance design, validation methodology, and post-deployment monitoring. The Epic Sepsis Model, IBM Watson for Oncology, and the Optum racial bias algorithm are documented examples of structurally deficient deployments that performed adequately in testing but failed under real-world conditions. The RIGOR™ System closes these structural gaps before deployment begins.
How does RIGOR™ relate to NIST AI RMF, EU AI Act, and FDA AI guidance?
RIGOR™ complements — not replaces — existing regulatory frameworks. NIST AI RMF provides a governance vocabulary. The EU AI Act establishes legal obligations. FDA AI/ML guidance outlines pre- and post-market requirements. RIGOR™ provides the operational engineering layer that translates governance principles into concrete engineering discipline at each lifecycle stage, while also generating the commercial evidence — payer reimbursement data, procurement documentation — that regulatory frameworks alone do not produce.
What is the difference between AI validation and AI monitoring?
AI validation (Operational Proof in RIGOR™) confirms that a system performs as required before deployment. AI monitoring (Runtime Monitoring in RIGOR™) is the ongoing surveillance of a deployed system for performance drift, bias emergence, and real-world outcome divergence — and critically, the source of real-world outcomes evidence that CMS requires for reimbursement and D&O insurers require for governance endorsements. Both are required; neither substitutes for the other.
What makes a clinical AI system deployment-grade?
A deployment-grade clinical AI system has: formally documented requirements with clinical and legal sign-off; an auditable implementation architecture with documented data lineage and bias controls; a governance layer with coded override mechanisms and audit logging; externally validated performance on demographically representative data; and active runtime monitoring for drift, bias, and outcome divergence — including tracking whether outputs are accepted or overridden and what outcomes follow. A system that meets only some of these criteria is not deployment-grade.
How does RIGOR™ address algorithmic bias in healthcare AI?
RIGOR™ addresses bias across three modules. In Requirements, performance metrics must include demographic disaggregation and bias review of proxy variables before development begins. In Implementation Architecture, bias checks are built into the data ingestion pipeline. In Runtime Monitoring, ongoing bias monitoring across protected demographic groups is a mandatory continuous obligation. The Optum racial bias algorithm operated for years without bias monitoring and was identified by external researchers — exactly what Runtime Monitoring is designed to prevent.
Can RIGOR™ System be applied outside of healthcare?
Yes. While RIGOR™ was developed in a healthcare context, the structural problems it addresses — high-stakes decisions on incomplete or poorly validated signals, absent governance, no post-deployment monitoring — appear across any sector where AI failure carries asymmetric consequences. Health AI has applied RIGOR™ in higher education AI literacy initiatives and enterprise manufacturing, including an AI-driven early warning system for a global tire manufacturer selected over Amazon, Microsoft, IBM, SAS, NTT Data, Dell, and Oracle.
Who developed the RIGOR™ System?
The RIGOR™ System was developed by Dr. Olga Lavinda, CEO and founder of Health AI LLC. Dr. Lavinda's background spans molecular pharmacology, chemometrics, and 15 years of translational science with NIH NRSA fellowship training. She is a member of the Coalition for Health AI (CHAI) and an Assistant Professor of Chemistry and Biochemistry. She is the only AI governance system developer who has also built and validated a consumer clinical AI product from scratch — Clarity, with 305 validated ingredients and 299 PubMed citations — demonstrating that what the RIGOR™ System describes is buildable, not theoretical.
Deploy the RIGOR™ System
Ready to build AI that proves its value after deployment?
Health AI works with healthcare organizations, medtech companies, and regulated enterprises to implement the RIGOR™ System. Every engagement produces documentation and evidence architecture your team owns permanently — no ongoing consulting dependency.
Get Your RIGOR™ AssessmentDownload the RIGOR™ System Playbook
Detailed module descriptions, crosswalk to NIST/FDA/EU standards, five case studies, and the complete deployment checklist.
About the Developer
Olga Lavinda, PhD
CEO and founder of Health AI LLC. Research scientist specializing in AI validation, polypharmacology, and translational science. NIH NRSA Fellow. Assistant Professor of Chemistry and Biochemistry. Member, Coalition for Health AI (CHAI). The only AI governance system developer who has also built and validated a consumer clinical AI product from scratch — demonstrating that what the RIGOR™ System describes is buildable, not theoretical. Selected over Amazon, Microsoft, IBM, SAS, NTT Data, Dell, and Oracle for a major enterprise AI engagement. olgalavinda.com · LinkedIn · @OlgaLavindaPhD
RIGOR™ System — AI Validation & Evidence Architecture — developed by Health AI LLC · healthai.com/insights · RIGOR™ System Product Page
Olga Lavinda, PhD · CEO, Health AI LLC · © 2026 Health AI LLC. RIGOR™ is a trademark of Health AI LLC.
Health AI LLC is a U.S.-based AI validation science firm. Not affiliated with HealthAI — the Global Agency for Responsible AI in Health (healthai.agency).